Errors, Uncertainty, and Residuals:
It is not uncommon for analytical chemists to use the terms, “error” and “uncertainty” somewhat interchangeably, although this can cause confusion. This section introduces both terms, as well as providing a more formal introduction to the concept of residuals. Whether error or uncertainty is used, however, the primary aim of such discussion in analytical chemistry is to determine (a) how close a result is to the ‘true’ value (the accuracy) and (b) how well replicate values agree with one another (the precision).
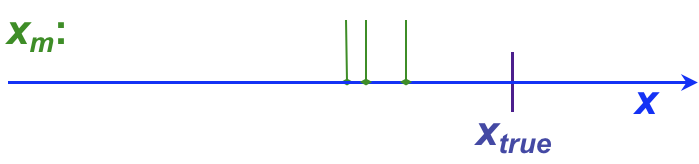
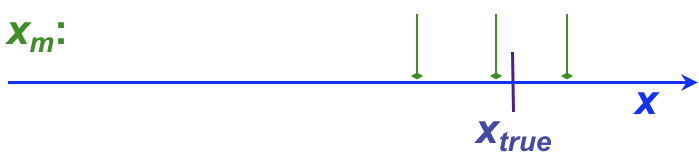
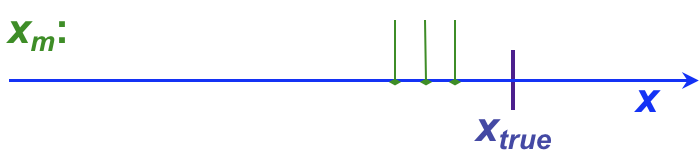

 , and has both sign and units. For example, the following table shows individual
measurements for the mass of sodium in a can of soup given previously, along with the mean value and residuals:
, and has both sign and units. For example, the following table shows individual
measurements for the mass of sodium in a can of soup given previously, along with the mean value and residuals: